Zákon binomického rozdělení. Zákon normálního rozdělení Rozdělení náhodné veličiny má tvar
Můžeme zdůraznit nejběžnější zákony distribuce diskrétních náhodných veličin:
- Zákon binomického rozdělení
- Poissonův distribuční zákon
- Zákon geometrického rozdělení
- Hypergeometrický distribuční zákon
Pro daná rozdělení diskrétních náhodných veličin se pomocí určitých „vzorců“ provádí výpočet pravděpodobností jejich hodnot a také numerických charakteristik (matematické očekávání, rozptyl atd.). Proto je velmi důležité znát tyto typy distribucí a jejich základní vlastnosti.
1. Zákon binomického rozdělení.
Diskrétní náhodná proměnná $X$ podléhá zákonu binomického rozdělení pravděpodobnosti, pokud nabývá hodnot $0,\ 1,\ 2,\ \tečky ,\ n$ s pravděpodobnostmi $P\left(X=k\right)= C^k_n\cdot p^k\cdot (\left(1-p\right))^(n-k)$. Ve skutečnosti je náhodná proměnná $X$ počet výskytů události $A$ v $n$ nezávislých studiích. Zákon rozdělení pravděpodobnosti náhodné veličiny $X$:
$\begin(pole)(|c|c|)
\hline
X_i & 0 & 1 & \tečky & n \\
\hline
p_i & P_n\left(0\vpravo) & P_n\left(1\vpravo) & \tečky & P_n\left(n\vpravo) \\
\hline
\end(pole)$
Pro takovou náhodnou veličinu je matematické očekávání $M\left(X\right)=np$, rozptyl je $D\left(X\right)=np\left(1-p\right)$.
Příklad . Rodina má dvě děti. Za předpokladu, že pravděpodobnost narození chlapce a dívky je 0,5 $, najděte zákon rozdělení náhodné veličiny $\xi$ - počet chlapců v rodině.
Nechť náhodná proměnná $\xi $ je počet chlapců v rodině. Hodnoty, které může $\xi nabývat:\ 0,\ 1,\ 2 $. Pravděpodobnosti těchto hodnot lze zjistit pomocí vzorce $P\left(\xi =k\right)=C^k_n\cdot p^k\cdot (\left(1-p\right))^(n-k )$, kde $n =2$ je počet nezávislých pokusů, $p=0,5$ je pravděpodobnost výskytu události v sérii $n$ pokusů. Dostáváme:
$P\left(\xi =0\right)=C^0_2\cdot (0,5)^0\cdot (\left(1-0,5\right))^(2-0)=(0, 5)^2=0,25;$
$P\left(\xi =1\right)=C^1_2\cdot 0,5\cdot (\left(1-0,5\right))^(2-1)=2\cdot 0,5\ cdot 0,5=0,5;$
$P\left(\xi =2\right)=C^2_2\cdot (0,5)^2\cdot (\left(1-0,5\right))^(2-2)=(0, 5)^2 = 0,25 $
Pak distribuční zákon náhodné veličiny $\xi $ je korespondence mezi hodnotami $0,\ 1,\ 2$ a jejich pravděpodobnostmi, to znamená:
$\begin(pole)(|c|c|)
\hline
\xi & 0 & 1 & 2 \\
\hline
P(\xi) & 0,25 & 0,5 & 0,25 \\
\hline
\end(pole)$
Součet pravděpodobností v distribučním zákoně by se měl rovnat $1$, tedy $\sum _(i=1)^(n)P(\xi _((\rm i)))=0,25+0,5+ 0, 25 = 1 $.
Očekávání $M\left(\xi \right)=np=2\cdot 0,5=1$, rozptyl $D\left(\xi \right)=np\left(1-p\right)=2\ cdot 0,5\ cdot 0,5=0,5$, standardní odchylka $\sigma \left(\xi \right)=\sqrt(D\left(\xi \right))=\sqrt(0,5)\cca 0,707 $.
2. Poissonův zákon rozdělení.
Pokud diskrétní náhodná proměnná $X$ může nabývat pouze nezáporné celočíselné hodnoty $0,\ 1,\ 2,\ \tečky,\ n$ s pravděpodobnostmi $P\left(X=k\right)=((( \lambda )^k )\přes (k}\cdot e^{-\lambda }$, то говорят, что она подчинена закону распределения Пуассона с параметром $\lambda $. Для такой случайной величины математическое ожидание и дисперсия равны между собой и равны параметру $\lambda $, то есть $M\left(X\right)=D\left(X\right)=\lambda $.!}
Komentář. Zvláštností tohoto rozdělení je, že na základě experimentálních dat zjistíme odhady $M\left(X\right),\D\left(X\right)$, pokud jsou získané odhady blízko sebe, pak máme důvod tvrdit, že náhodná veličina podléhá Poissonově distribučnímu zákonu.
Příklad . Příklady náhodných proměnných podléhajících zákonu Poissonova rozdělení mohou být: počet vozů, které zítra obslouží čerpací stanice; počet vadných položek ve vyrobených produktech.
Příklad . Továrna poslala na základnu produkty za 500 $. Pravděpodobnost poškození produktu při přepravě je 0,002 $. Najděte zákon rozdělení náhodné veličiny $X$ rovný počtu poškozených produktů; co je $M\left(X\right),\D\left(X\right)$.
Nechť diskrétní náhodná proměnná $X$ je počet poškozených produktů. Taková náhodná veličina podléhá Poissonově zákonu rozdělení s parametrem $\lambda =np=500\cdot 0,002=1$. Pravděpodobnosti hodnot se rovnají $P\left(X=k\right)=(((\lambda )^k)\over (k}\cdot e^{-\lambda }$. Очевидно, что все вероятности всех значений $X=0,\ 1,\ \dots ,\ 500$ перечислить невозможно, поэтому мы ограничимся лишь первыми несколькими значениями.!}
$P\left(X=0\right)=((1^0)\over (0}\cdot e^{-1}=0,368;$!}
$P\left(X=1\right)=((1^1)\over (1}\cdot e^{-1}=0,368;$!}
$P\left(X=2\right)=((1^2)\over (2}\cdot e^{-1}=0,184;$!}
$P\left(X=3\right)=((1^3)\over (3}\cdot e^{-1}=0,061;$!}
$P\left(X=4\right)=((1^4)\over (4}\cdot e^{-1}=0,015;$!}
$P\left(X=5\right)=((1^5)\over (5}\cdot e^{-1}=0,003;$!}
$P\left(X=6\right)=((1^6)\over (6}\cdot e^{-1}=0,001;$!}
$P\left(X=k\right)=(((\lambda )^k)\přes (k}\cdot e^{-\lambda }$!}
Zákon rozdělení náhodné veličiny $X$:
$\begin(pole)(|c|c|)
\hline
X_i & 0 & 1 & 2 & 3 & 4 & 5 & 6 & ... & k \\
\hline
P_i & 0,368; & 0,368 & 0,184 & 0,061 & 0,015 & 0,003 & 0,001 & ... & (((\lambda )^k)\přes (k}\cdot e^{-\lambda } \\!}
\hline
\end(pole)$
Pro takovou náhodnou veličinu jsou matematické očekávání a rozptyl stejné a rovny parametru $\lambda $, tedy $M\left(X\right)=D\left(X\right)=\lambda = 1 $.
3. Zákon geometrického rozdělení.
Pokud diskrétní náhodná proměnná $X$ může nabývat pouze přirozené hodnoty $1,\ 2,\ \tečky,\ n$ s pravděpodobnostmi $P\left(X=k\right)=p(\left(1-p\) vpravo)) ^(k-1),\ k=1,\ 2,\ 3,\ \tečky $, pak říkají, že taková náhodná veličina $X$ podléhá geometrickému zákonu rozdělení pravděpodobnosti. Ve skutečnosti je geometrické rozložení až do prvního úspěchu Bernoulliho testem.
Příklad . Příklady náhodných proměnných, které mají geometrické rozložení, mohou být: počet výstřelů před prvním zásahem do cíle; počet testů zařízení do prvního selhání; počet hodů mincí, dokud se neobjeví první hlava atd.
Matematické očekávání a rozptyl náhodné veličiny podléhající geometrickému rozdělení se rovnají $M\left(X\right)=1/p$, $D\left(X\right)=\left(1-p\right) )/p^ $ 2.
Příklad . Na cestě pohybu ryb k místu tření je zámek 4 $. Pravděpodobnost, že ryby projdou každou bránou, je $p=3/5$. Sestrojte řadu rozdělení náhodné veličiny $X$ - počet plavebních komor, které ryba prošla před prvním zadržením u zdymadla. Najděte $M\left(X\right),\D\left(X\right),\ \sigma \left(X\right)$.
Nechť náhodná proměnná $X$ je počet zámků, které ryba prošla před prvním zadržením u zámku. Taková náhodná veličina podléhá geometrickému zákonu rozdělení pravděpodobnosti. Hodnoty, které může náhodná proměnná $X nabývat: $ 1, 2, 3, 4. Pravděpodobnosti těchto hodnot se počítají pomocí vzorce: $P\left(X=k\right)=pq^(k -1)$, kde: $ p=2/5$ - pravděpodobnost zadržení ryb přes zdymadlo, $q=1-p=3/5$ - pravděpodobnost proplutí ryb zdymadlem, $k=1,\ 2,\ 3,\ 4 $.
$P\left(X=1\vpravo)=((2)\přes (5))\cdot (\left(((3)\přes (5))\vpravo))^0=((2)\ nad (5)) = 0,4; $
$P\left(X=2\vpravo)=((2)\přes (5))\cdot ((3)\přes (5))=((6)\přes (25))=0,24 $
$P\left(X=3\right)=((2)\over (5))\cdot (\left(((3)\over (5))\right))^2=((2)\ přes (5))\cdot ((9)\přes (25))=((18)\přes (125))=0,144;$
$P\left(X=4\right)=((2)\přes (5))\cdot (\left(((3)\over (5))\right))^3+(\left(( (3)\přes (5))\vpravo))^4=((27)\přes (125))=0,216,$
$\begin(pole)(|c|c|)
\hline
X_i & 1 & 2 & 3 & 4 \\
\hline
P\left(X_i\right) & 0,4 & 0,24 & 0,144 & 0,216 \\
\hline
\end(pole)$
Matematické očekávání:
$M\left(X\right)=\sum^n_(i=1)(x_ip_i)=1\cdot 0,4+2\cdot 0,24+3\cdot 0,144+4\cdot 0,216=2,176,$
Rozptyl:
$D\left(X\right)=\sum^n_(i=1)(p_i(\left(x_i-M\left(X\right)\right))^2=)0,4\cdot (\ left( 1-2 176\right))^2+0.24\cdot (\left(2-2.176\right))^2+0.144\cdot (\left(3-2.176\right))^2+$
$+\0,216\cdot (\left(4-2,176\right))^2\cca 1,377,$
Směrodatná odchylka:
$\sigma \left(X\right)=\sqrt(D\left(X\right))=\sqrt(1,377)\cca 1,173,$
4. Hypergeometrický distribuční zákon.
If $N$ objektů, mezi nimiž $m$ objekty mají danou vlastnost. Objekty $n$ jsou náhodně získávány bez vracení, mezi nimiž bylo $k$ objektů, které mají danou vlastnost. Hypergeometrické rozdělení umožňuje odhadnout pravděpodobnost, že právě $k$ objektů ve vzorku má danou vlastnost. Nechť náhodná proměnná $X$ je počet objektů ve vzorku, které mají danou vlastnost. Pak pravděpodobnosti hodnot náhodné proměnné $X$:
$P\left(X=k\right)=((C^k_mC^(n-k)_(N-m))\přes (C^n_N))$
Komentář. Statistická funkce HYPERGEOMET průvodce funkcí Excel $f_x$ umožňuje určit pravděpodobnost, že určitý počet testů bude úspěšný.
$f_x\to$ statistický$\to$ HYPERGEOMET$\to$ OK. Zobrazí se dialogové okno, které musíte vyplnit. Ve sloupci Počet_úspěchů_v_vzorku uveďte hodnotu $k$. velikost_vzorku se rovná $n$. Ve sloupci Počet_úspěchů_v_spolu uveďte hodnotu $m$. velikost_populace rovná se $N$.
Matematické očekávání a rozptyl diskrétní náhodné proměnné $X$, podléhající zákonu o geometrickém rozdělení, se rovnají $M\left(X\right)=nm/N$, $D\left(X\right)= ((nm\vlevo(1 -((m)\přes (N))\vpravo)\vlevo (1-((n)\přes (N))\vpravo))\přes (N-1))$.
Příklad . Úvěrové oddělení banky zaměstnává 5 specialistů s vyšším finančním vzděláním a 3 specialisty s vyšším právním vzděláním. Vedení banky se rozhodlo vyslat 3 specialisty ke zvýšení kvalifikace, které vybralo v náhodném pořadí.
a) Vytvořte distribuční řadu pro počet specialistů s vyšším finančním vzděláním, kteří mohou být vysláni, aby zlepšili své dovednosti;
b) Najděte číselné charakteristiky tohoto rozdělení.
Nechť náhodná veličina $X$ je počet specialistů s vyšším finančním vzděláním mezi třemi vybranými. Hodnoty, které může $X nabývat: 0,\ 1,\ 2,\ 3 $. Tato náhodná veličina $X$ je distribuována podle hypergeometrického rozdělení s následujícími parametry: $N=8$ - velikost populace, $m=5$ - počet úspěchů v populaci, $n=3$ - velikost vzorku, $ k=0,\ 1, \2,\3$ - počet úspěchů ve vzorku. Potom lze pravděpodobnosti $P\left(X=k\right)$ vypočítat pomocí vzorce: $P(X=k)=(C_(m)^(k) \cdot C_(N-m)^(n-k) \ přes C_(N)^(n)) $. máme:
$P\left(X=0\right)=((C^0_5\cdot C^3_3)\over (C^3_8))=((1)\over (56))\cca 0,018;$
$P\left(X=1\right)=((C^1_5\cdot C^2_3)\over (C^3_8))=((15)\over (56))\cca 0,268;$
$P\left(X=2\right)=((C^2_5\cdot C^1_3)\over (C^3_8))=((15)\over (28))\cca 0,536;$
$P\left(X=3\right)=((C^3_5\cdot C^0_3)\over (C^3_8))=((5)\over (28))\cca 0,179,$
Potom distribuční řada náhodné veličiny $X$:
$\begin(pole)(|c|c|)
\hline
X_i & 0 & 1 & 2 & 3 \\
\hline
p_i & 0,018 & 0,268 & 0,536 & 0,179 \\
\hline
\end(pole)$
Vypočítejme číselné charakteristiky náhodné veličiny $X$ pomocí obecných vzorců hypergeometrického rozdělení.
$M\levý(X\vpravo)=((nm)\přes (N))=((3\cdot 5)\přes (8))=((15)\přes (8))=1 875,$
$D\left(X\right)=((nm\left(1-((m)\over (N))\right)\left(1-((n)\over (N))\right)) \over (N-1))=((3\cdot 5\cdot \left(1-((5)\over (8))\right)\cdot \left(1-((3)\over (8) ))\vpravo))\přes (8-1))=((225)\přes (448))\přibližně 0,502,$
$\sigma \left(X\right)=\sqrt(D\left(X\right))=\sqrt(0,502)\cca 0,7085,$
Náhodná proměnná Proměnná se nazývá proměnná, která v důsledku každého testu nabývá jedné dříve neznámé hodnoty v závislosti na náhodných důvodech. Náhodné proměnné se označují velkými latinskými písmeny: $X,\ Y,\ Z,\ \dots $ Náhodné proměnné mohou být podle svého typu diskrétní A kontinuální.
Diskrétní náhodná veličina- toto je náhodná proměnná, jejíž hodnoty nemohou být více než spočítatelné, to znamená buď konečné, nebo spočítatelné. Počitatelností rozumíme, že hodnoty náhodné veličiny lze očíslovat.
Příklad 1 . Zde jsou příklady diskrétních náhodných proměnných:
a) počet zásahů do cíle pomocí $n$ ran, zde možné hodnoty jsou $0,\ 1,\ \tečky,\ n$.
b) počet odložených emblémů při hodu mincí, zde jsou možné hodnoty $0,\ 1,\ \tečky,\n$.
c) počet lodí připlouvajících na palubu (spočetný soubor hodnot).
d) počet hovorů přicházejících na ústřednu (spočetný soubor hodnot).
1. Zákon rozdělení pravděpodobnosti diskrétní náhodné veličiny.
Diskrétní náhodná proměnná $X$ může nabývat hodnot $x_1,\tečky ,\ x_n$ s pravděpodobnostmi $p\left(x_1\right),\ \dots ,\ p\left(x_n\right)$. Korespondence mezi těmito hodnotami a jejich pravděpodobnostmi se nazývá zákon rozdělení diskrétní náhodné veličiny. Tato korespondence je zpravidla specifikována pomocí tabulky, jejíž první řádek označuje hodnoty $x_1,\tečky ,\ x_n$ a druhý řádek obsahuje pravděpodobnosti $p_1,\tečky ,\ p_n$ odpovídající tyto hodnoty.
$\begin(pole)(|c|c|)
\hline
X_i & x_1 & x_2 & \dots & x_n \\
\hline
p_i & p_1 & p_2 & \tečky & p_n \\
\hline
\end(pole)$
Příklad 2 . Nechť náhodná proměnná $X$ je počet hozených bodů při hodu kostkou. Taková náhodná proměnná $X$ může nabývat následujících hodnot: $1,\ 2,\ 3,\ 4,\ 5,\ 6$. Pravděpodobnost všech těchto hodnot se rovná $ 1/6 $. Pak zákon rozdělení pravděpodobnosti náhodné veličiny $X$:
$\begin(pole)(|c|c|)
\hline
1 & 2 & 3 & 4 & 5 & 6 \\
\hline
\hline
\end(pole)$
Komentář. Protože v distribučním zákoně diskrétní náhodné veličiny $X$ tvoří události $1,\ 2,\ \tečky ,\ 6$ úplnou skupinu událostí, pak se součet pravděpodobností musí rovnat jedné, tedy $ \sum(p_i)=1$.
2. Matematické očekávání diskrétní náhodné veličiny.
Očekávání náhodné veličiny určuje jeho „ústřední“ význam. Pro diskrétní náhodnou veličinu se matematické očekávání vypočítá jako součet součinů hodnot $x_1,\tečky ,\ x_n$ a pravděpodobností $p_1,\tečky,\p_n$ odpovídajících těmto hodnotám, tzn. : $M\left(X\vpravo)=\součet ^n_(i=1)(p_ix_i)$. V anglicky psané literatuře se používá jiný zápis $E\left(X\right)$.
Vlastnosti matematického očekávání$M\levý(X\vpravo)$:
- $M\left(X\right)$ leží mezi nejmenší a největší hodnotou náhodné proměnné $X$.
- Matematické očekávání konstanty se rovná konstantě samotné, tzn. $M\left(C\right)=C$.
- Konstantní faktor lze vyjmout ze znaménka matematického očekávání: $M\left(CX\right)=CM\left(X\right)$.
- Matematické očekávání součtu náhodných proměnných se rovná součtu jejich matematických očekávání: $M\left(X+Y\right)=M\left(X\right)+M\left(Y\right)$.
- Matematické očekávání součinu nezávislých náhodných veličin se rovná součinu jejich matematických očekávání: $M\left(XY\right)=M\left(X\right)M\left(Y\right)$.
Příklad 3 . Najdeme matematické očekávání náhodné veličiny $X$ z příkladu $2$.
$$M\left(X\right)=\sum^n_(i=1)(p_ix_i)=1\cdot ((1)\over (6))+2\cdot ((1)\over (6) )+3\cdot ((1)\nad (6))+4\cdot ((1)\nad (6))+5\cdot ((1)\přes (6))+6\cdot ((1) )\přes (6))=3,5.$$
Můžeme si všimnout, že $M\left(X\right)$ leží mezi nejmenší ($1$) a největší ($6$) hodnotou náhodné proměnné $X$.
Příklad 4 . Je známo, že matematické očekávání náhodné veličiny $X$ se rovná $M\left(X\right)=2$. Najděte matematické očekávání náhodné proměnné $3X+5$.
Pomocí výše uvedených vlastností získáme $M\left(3X+5\right)=M\left(3X\right)+M\left(5\right)=3M\left(X\right)+5=3\ cdot 2 +5 = 11 $.
Příklad 5 . Je známo, že matematické očekávání náhodné veličiny $X$ se rovná $M\left(X\right)=4$. Najděte matematické očekávání náhodné veličiny $2X-9$.
Pomocí výše uvedených vlastností získáme $M\left(2X-9\right)=M\left(2X\right)-M\left(9\right)=2M\left(X\right)-9=2\ cdot 4 -9=-1$.
3. Disperze diskrétní náhodné veličiny.
Možné hodnoty náhodných proměnných se stejnými matematickými očekáváními se mohou kolem jejich průměrných hodnot rozptýlit různě. Například ve dvou studentských skupinách bylo průměrné skóre u zkoušky z teorie pravděpodobnosti 4, ale v jedné skupině byli všichni dobří studenti a ve druhé skupině byli pouze studenti C a výborní studenti. Proto je potřeba číselné charakteristiky náhodné veličiny, která by ukazovala rozptyl hodnot náhodné veličiny kolem jejího matematického očekávání. Touto vlastností je disperze.
Rozptyl diskrétní náhodné veličiny$X$ se rovná:
$$D\left(X\right)=\sum^n_(i=1)(p_i(\left(x_i-M\left(X\right)\right))^2).\ $$
V anglické literatuře se používá zápis $V\left(X\right),\ Var\left(X\right)$. Velmi často se rozptyl $D\left(X\right)$ počítá pomocí vzorce $D\left(X\right)=\sum^n_(i=1)(p_ix^2_i)-(\left(M\ vlevo(X \vpravo)\vpravo))^2$.
Disperzní vlastnosti$D\levý(X\vpravo)$:
- Rozptyl je vždy větší nebo roven nule, tzn. $D\left(X\right)\ge 0$.
- Rozptyl konstanty je nulový, tzn. $D\left(C\right)=0$.
- Konstantní faktor lze vyjmout ze znaménka rozptylu za předpokladu, že je na druhou, tzn. $D\left(CX\right)=C^2D\left(X\right)$.
- Rozptyl součtu nezávislých náhodných veličin je roven součtu jejich rozptylů, tzn. $D\left(X+Y\right)=D\left(X\right)+D\left(Y\right)$.
- Rozptyl rozdílu mezi nezávislými náhodnými veličinami je roven součtu jejich rozptylů, tzn. $D\left(X-Y\right)=D\left(X\right)+D\left(Y\right)$.
Příklad 6 . Vypočítejme rozptyl náhodné veličiny $X$ z příkladu $2$.
$$D\left(X\right)=\sum^n_(i=1)(p_i(\left(x_i-M\left(X\right)\right))^2)=((1)\over (6))\cdot (\left(1-3.5\right))^2+((1)\over (6))\cdot (\left(2-3.5\right))^2+ \tečky +( (1)\přes (6))\cdot (\left(6-3,5\right))^2=((35)\přes (12))\cca 2,92,$$
Příklad 7 . Je známo, že rozptyl náhodné veličiny $X$ je roven $D\left(X\right)=2$. Najděte rozptyl náhodné veličiny $4X+1$.
Pomocí výše uvedených vlastností najdeme $D\left(4X+1\right)=D\left(4X\right)+D\left(1\right)=4^2D\left(X\right)+0= 16D\ vlevo(X\vpravo)=16\cdot 2=32$.
Příklad 8 . Je známo, že rozptyl náhodné veličiny $X$ je roven $D\left(X\right)=3$. Najděte rozptyl náhodné veličiny $3-2X$.
Pomocí výše uvedených vlastností najdeme $D\left(3-2X\right)=D\left(3\right)+D\left(2X\right)=0+2^2D\left(X\right)= 4D\ vlevo(X\vpravo)=4\cdot 3=12$.
4. Distribuční funkce diskrétní náhodné veličiny.
Způsob reprezentace diskrétní náhodné veličiny ve formě distribuční řady není jediný a hlavně není univerzální, protože spojitou náhodnou veličinu nelze specifikovat pomocí distribuční řady. Existuje další způsob, jak reprezentovat náhodnou veličinu - distribuční funkce.
Distribuční funkce náhodná proměnná $X$ se nazývá funkce $F\left(x\right)$, která určuje pravděpodobnost, že náhodná proměnná $X$ bude mít hodnotu menší než nějaká pevná hodnota $x$, tedy $F\ left(x\right)=P\left(X< x\right)$
Vlastnosti distribuční funkce:
- $0\le F\left(x\right)\le 1$.
- Pravděpodobnost, že náhodná proměnná $X$ bude nabývat hodnot z intervalu $\left(\alpha ;\ \beta \right)$, se rovná rozdílu mezi hodnotami distribuční funkce na koncích tohoto interval: $P\left(\alpha< X < \beta \right)=F\left(\beta \right)-F\left(\alpha \right)$
- $F\left(x\right)$ - neklesající.
- $(\mathop(lim)_(x\to -\infty ) F\left(x\right)=0\ ),\ (\mathop(lim)_(x\to +\infty ) F\left(x \right)=1\ )$.
Příklad 9 . Najdeme distribuční funkci $F\left(x\right)$ pro distribuční zákon diskrétní náhodné veličiny $X$ z příkladu $2$.
$\begin(pole)(|c|c|)
\hline
1 & 2 & 3 & 4 & 5 & 6 \\
\hline
1/6 & 1/6 & 1/6 & 1/6 & 1/6 & 1/6 \\
\hline
\end(pole)$
Pokud $x\le 1$, pak samozřejmě $F\left(x\right)=0$ (včetně pro $x=1$ $F\left(1\right)=P\left(X< 1\right)=0$).
Pokud 1 $< x\le 2$, то $F\left(x\right)=P\left(X=1\right)=1/6$.
Pokud 2 $< x\le 3$, то $F\left(x\right)=P\left(X=1\right)+P\left(X=2\right)=1/6+1/6=1/3$.
Pokud 3 $< x\le 4$, то $F\left(x\right)=P\left(X=1\right)+P\left(X=2\right)+P\left(X=3\right)=1/6+1/6+1/6=1/2$.
Pokud 4 $< x\le 5$, то $F\left(X\right)=P\left(X=1\right)+P\left(X=2\right)+P\left(X=3\right)+P\left(X=4\right)=1/6+1/6+1/6+1/6=2/3$.
Pokud 5 dolarů< x\le 6$, то $F\left(x\right)=P\left(X=1\right)+P\left(X=2\right)+P\left(X=3\right)+P\left(X=4\right)+P\left(X=5\right)=1/6+1/6+1/6+1/6+1/6=5/6$.
Pokud $x > 6$, pak $F\levá (x\vpravo)=P\levá (X=1\vpravo)+P\levá (X=2\vpravo)+P\levá (X=3\vpravo) +P\doleva(X=4\vpravo)+P\doleva (X=5\vpravo)+P\doleva (X=6\vpravo)=1/6+1/6+1/6+1/6+ 1/6 + 1/6 = 1 $.
Takže $F(x)=\left\(\begin(matice)
0,\ v\ x\le 1,\\
1/6, v\ 1< x\le 2,\\
1/3,\ v\ 2< x\le 3,\\
1/2, v\ 3< x\le 4,\\
2/3,\ v\ 4< x\le 5,\\
6. 5., v 4< x\le 5,\\
1,\ pro\ x > 6.
\end(matice)\right.$
Příklady náhodných proměnných distribuovaných podle normálního zákona jsou výška osoby a hmotnost ulovených ryb stejného druhu. Normální distribuce znamená následující : existují hodnoty lidské výšky, hmotnosti ryb stejného druhu, které jsou intuitivně vnímány jako „normální“ (a ve skutečnosti zprůměrované) a v dostatečně velkém vzorku se nacházejí mnohem častěji než ty, které se liší směrem nahoru nebo dolů.
Normální rozdělení pravděpodobnosti spojité náhodné veličiny (někdy Gaussovo rozdělení) lze nazvat zvonovité kvůli skutečnosti, že funkce hustoty tohoto rozdělení, symetrická ke střední hodnotě, je velmi podobná řezu zvonu (červená křivka na obrázku výše).
Pravděpodobnost setkání s určitými hodnotami ve vzorku se rovná ploše obrázku pod křivkou a v případě normálního rozdělení vidíme, že pod vrcholem „zvonku“, což odpovídá hodnotám při sklonu k průměru je plocha, a tedy i pravděpodobnost, větší než pod okraji. Dostáváme tedy totéž, co již bylo řečeno: pravděpodobnost setkání s osobou „normální“ výšky a ulovení ryby „normální“ hmotnosti je vyšší než u hodnot, které se liší směrem nahoru nebo dolů. V mnoha praktických případech jsou chyby měření rozděleny podle zákona blízkého normálu.
Podívejme se znovu na obrázek na začátku lekce, který ukazuje funkci hustoty normálního rozdělení. Graf této funkce byl získán výpočtem určitého vzorku dat v softwarovém balíku STATISTIKA. Sloupce histogramu na něm představují intervaly vzorových hodnot, jejichž rozložení se blíží (nebo, jak se ve statistikách běžně říká, výrazně neliší) skutečnému grafu funkce hustoty normálního rozdělení, což je červená křivka . Graf ukazuje, že tato křivka má skutečně tvar zvonu.
Normální rozdělení je cenné v mnoha ohledech, protože pokud znáte pouze očekávanou hodnotu spojité náhodné proměnné a její směrodatnou odchylku, můžete vypočítat jakoukoli pravděpodobnost spojenou s touto proměnnou.
Normální rozdělení má také tu výhodu, že je jedním z nejjednodušších na použití. statistické testy používané k testování statistických hypotéz - Studentův t test- lze použít pouze v případě, že vzorová data splňují zákon normálního rozdělení.
Funkce hustoty normálního rozdělení spojité náhodné veličiny lze najít pomocí vzorce:
 ,
,
Kde x- hodnota měnící se veličiny, - průměrná hodnota, - směrodatná odchylka, E=2,71828... - základna přirozeného logaritmu, =3,1416...
Vlastnosti funkce hustoty normálního rozdělení
Změny v průměru posouvají funkční křivku normální hustoty směrem k ose Vůl. Pokud se zvýší, křivka se posune doprava, pokud se sníží, pak doleva.
Pokud se změní směrodatná odchylka, změní se výška vrcholu křivky. Když se směrodatná odchylka zvýší, vrchol křivky je vyšší, a když se sníží, je nižší.
Pravděpodobnost normálně rozdělené náhodné veličiny spadající do daného intervalu
Již v tomto odstavci začneme řešit praktické problémy, jejichž význam je naznačen v názvu. Podívejme se, jaké možnosti poskytuje teorie pro řešení problémů. Výchozím konceptem pro výpočet pravděpodobnosti normálně rozdělené náhodné veličiny spadající do daného intervalu je kumulativní funkce normálního rozdělení.
Kumulativní normální distribuční funkce:
 .
.
Je však problematické získat tabulky pro každou možnou kombinaci průměru a směrodatné odchylky. Proto jedním z jednoduchých způsobů, jak vypočítat pravděpodobnost normálně rozdělené náhodné veličiny spadající do daného intervalu, je použití pravděpodobnostních tabulek pro standardizované normální rozdělení.
Normální rozdělení se nazývá standardizované nebo normalizované., jehož průměr je a směrodatná odchylka je .
Standardizovaná funkce hustoty normální distribuce:
![]() .
.
Kumulativní funkce standardizovaného normálního rozdělení:
 .
.
Níže uvedený obrázek ukazuje integrální funkci standardizovaného normálního rozdělení, jehož graf byl získán výpočtem určitého vzorku dat v softwarovém balíku STATISTIKA. Samotný graf je červená křivka a hodnoty vzorku se k ní blíží.

Pro zvětšení obrázku na něj můžete kliknout levým tlačítkem myši.
Standardizace náhodné veličiny znamená přechod od původních jednotek použitých v úloze k jednotkám standardizovaným. Standardizace se provádí podle vzorce
V praxi jsou všechny možné hodnoty náhodné veličiny často neznámé, takže hodnoty střední hodnoty a směrodatné odchylky nelze přesně určit. Jsou nahrazeny aritmetickým průměrem pozorování a standardní odchylkou s. Velikost z vyjadřuje odchylky hodnot náhodné veličiny od aritmetického průměru při měření směrodatných odchylek.
Otevřený interval
Pravděpodobnostní tabulka pro standardizované normální rozdělení, kterou lze nalézt v téměř každé knize o statistice, obsahuje pravděpodobnosti, že náhodná veličina se standardním normálním rozdělením Z bude mít hodnotu menší než určité číslo z. To znamená, že bude spadat do otevřeného intervalu od mínus nekonečna do z. Například pravděpodobnost, že množství Z menší než 1,5, rovná se 0,93319.
Příklad 1 Společnost vyrábí díly, jejichž životnost je běžně rozložena s průměrem 1000 hodin a standardní odchylkou 200 hodin.
Pro náhodně vybraný díl vypočítejte pravděpodobnost, že jeho životnost bude minimálně 900 hodin.
Řešení. Pojďme si představit první zápis:
Požadovaná pravděpodobnost.
Hodnoty náhodných proměnných jsou v otevřeném intervalu. Ale víme, jak spočítat pravděpodobnost, že náhodná veličina bude mít hodnotu menší než daná, a podle podmínek problému potřebujeme najít stejnou nebo větší než daná. Toto je druhá část prostoru pod normální křivkou hustoty (zvonek). Proto, abyste našli požadovanou pravděpodobnost, musíte od jednoty odečíst zmíněnou pravděpodobnost, že náhodná veličina bude mít hodnotu menší než zadaných 900:
Nyní je potřeba náhodnou veličinu standardizovat.
Pokračujeme v zavádění notace:
z = (X ≤ 900) ;
x= 900 - zadaná hodnota náhodné veličiny;
μ = 1000 - průměrná hodnota;
σ = 200 - standardní odchylka.
Pomocí těchto údajů získáme podmínky problému:
![]() .
.
Podle tabulek standardizované náhodné veličiny (intervalová hranice) z= −0,5 odpovídá pravděpodobnosti 0,30854. Odečtěte to od jednoty a získejte to, co je požadováno v příkazu problému:
Pravděpodobnost, že díl bude mít životnost minimálně 900 hodin, je tedy 69 %.
Tuto pravděpodobnost lze získat pomocí funkce MS Excel NORM.DIST (celková hodnota - 1):
P(X≥900) = 1 - P(X≤900) = 1 - NORM.DIST(900; 1000; 200; 1) = 1 - 0,3085 = 0,6915.
O výpočtech v MS Excel - v jednom z následujících odstavců této lekce.
Příklad 2 V určitém městě je průměrný roční příjem rodiny normálně rozdělená náhodná veličina s průměrem 300 000 a směrodatnou odchylkou 50 000. Je známo, že příjem 40 % rodin je nižší než A. Najděte hodnotu A.
Řešení. V tomto problému není 40 % nic jiného než pravděpodobnost, že náhodná proměnná nabude hodnotu z otevřeného intervalu, která je menší než určitá hodnota, označená písmenem A.
Chcete-li zjistit hodnotu A, nejprve složíme integrální funkci:
![]()
Podle podmínek problému
μ = 300000 - průměrná hodnota;
σ = 50000 - směrodatná odchylka;
x = A- množství, které má být nalezeno.
Vytváření rovnosti
![]() .
.
Ze statistických tabulek zjistíme, že pravděpodobnosti 0,40 odpovídá hodnota hranice intervalu z = −0,25 .
Proto vytváříme rovnost
![]()
a najít jeho řešení:
A = 287300 .
Odpověď: 40 % rodin má příjmy nižší než 287 300.
Uzavřený interval
V mnoha problémech je potřeba najít pravděpodobnost, že normálně rozložená náhodná veličina nabude hodnoty v intervalu od z 1 až z 2. To znamená, že bude spadat do uzavřeného intervalu. K vyřešení takových úloh je nutné najít v tabulce pravděpodobnosti odpovídající hranicím intervalu a následně najít rozdíl mezi těmito pravděpodobnostmi. To vyžaduje odečtení menší hodnoty od větší. Příklady řešení těchto běžných problémů jsou následující a budete požádáni, abyste je vyřešili sami, a poté uvidíte správná řešení a odpovědi.
Příklad 3 Zisk podniku za určité období je náhodná veličina podléhající zákonu o běžném rozdělení s průměrnou hodnotou 0,5 milionu. a standardní odchylka 0,354. Určete s přesností na dvě desetinná místa pravděpodobnost, že zisk podniku bude od 0,4 do 0,6 c.u.
Příklad 4. Délka vyráběného dílu je náhodná veličina rozdělená podle normálního zákona s parametry μ = 10 a σ =0,071. Najděte pravděpodobnost vad s přesností na dvě desetinná místa, pokud přípustné rozměry součásti musí být 10±0,05.
Nápověda: v tomto problému je potřeba kromě zjištění pravděpodobnosti pádu náhodné veličiny do uzavřeného intervalu (pravděpodobnost obdržení nezávadného dílu) provést ještě jednu akci.
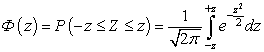
umožňuje určit pravděpodobnost, že standardizovaná hodnota Z ne méně -z a nic víc +z, Kde z- libovolně zvolená hodnota standardizované náhodné veličiny.
Přibližná metoda pro kontrolu normality rozdělení
Přibližná metoda pro kontrolu normality distribuce hodnot vzorku je založena na následujícím vlastnost normálního rozdělení: koeficient šikmosti β 1 a koeficient špičatosti β 2 se rovnají nule.
Koeficient asymetrie β 1 číselně charakterizuje symetrii empirického rozdělení vzhledem k průměru. Pokud je koeficient šikmosti nula, pak jsou aritmetrický průměr, medián a modus stejné: a křivka hustoty distribuce je symetrická k průměru. Pokud je koeficient asymetrie menší než nula (β 1 < 0 ), pak je aritmetický průměr menší než medián a medián je zase menší než modus () a křivka je posunuta doprava (oproti normálnímu rozdělení). Pokud je koeficient asymetrie větší než nula (β 1 > 0 ), pak je aritmetický průměr větší než medián a medián je zase větší než modus () a křivka je posunuta doleva (oproti normálnímu rozdělení).
Kurtózní koeficient β 2 charakterizuje koncentraci empirického rozdělení kolem aritmetického průměru ve směru osy Oj a stupeň vrcholení křivky hustoty distribuce. Pokud je koeficient špičatosti větší než nula, pak je křivka více protáhlá (ve srovnání s normálním rozdělením) podél osy Oj(graf je více špičatý). Pokud je koeficient špičatosti menší než nula, pak je křivka více zploštělá (ve srovnání s normálním rozdělením) podél osy Oj(graf je tupější).
Koeficient asymetrie lze vypočítat pomocí funkce MS Excel SKOS. Pokud kontrolujete jedno datové pole, musíte zadat rozsah dat do jednoho pole „Číslo“.

Koeficient špičatosti lze vypočítat pomocí funkce MS Excel KURTESS. Při kontrole jednoho datového pole také stačí zadat rozsah dat do jednoho pole „Číslo“.

Takže, jak již víme, s normálním rozdělením jsou koeficienty šikmosti a špičatosti rovny nule. Ale co když dostaneme koeficienty šikmosti -0,14, 0,22, 0,43 a koeficienty špičatosti 0,17, -0,31, 0,55? Otázka je docela spravedlivá, protože v praxi se zabýváme pouze přibližnými, vzorovými hodnotami asymetrie a špičatosti, které podléhají určitému nevyhnutelnému, nekontrolovanému rozptylu. Nelze tedy požadovat, aby se tyto koeficienty přísně rovnaly nule, musí se pouze dostatečně blížit nule. Ale co znamená dost?
Je nutné porovnat získané empirické hodnoty s přijatelnými hodnotami. Chcete-li to provést, musíte zkontrolovat následující nerovnosti (porovnat hodnoty modulových koeficientů s kritickými hodnotami - hranicemi oblasti testování hypotézy).
Pro koeficient asymetrie β 1 .
Uvažujme diskrétní distribuce, které se často používají při modelování servisních systémů.
Bernoulliho distribuce. Bernoulliho schéma je posloupnost nezávislých pokusů, v každém z nich jsou možné pouze dva výsledky – „úspěch“ a „neúspěch“ s pravděpodobnostmi. r A q = 1 - r. Nechť náhodnou veličinu X může nabývat dvou hodnot s odpovídajícími pravděpodobnostmi:
Bernoulliho distribuční funkce má tvar
Jeho graf je na Obr. 11.1.
Náhodná veličina s takovým rozdělením se rovná počtu úspěchů v jednom pokusu Bernoulliho schématu.
Generující funkce podle (11.1) a (11.15) se vypočítá jako
Rýže. 11.1.

Pomocí vzorce (11.6) najdeme matematické očekávání rozdělení:
Vypočítejme druhou derivaci generující funkce pomocí (11.17)
Z (11.7) získáme disperzi rozdělení
Bernoulliho rozdělení hraje velkou roli v teorii hromadné služby, je modelem jakéhokoli náhodného experimentu, jehož výsledky patří do dvou vzájemně se vylučujících tříd.
Geometrické rozložení. Předpokládejme, že události probíhají v diskrétních časech nezávisle na sobě. Pravděpodobnost, že k události dojde, se rovná p, a pravděpodobnost, že se to nestane, je q = 1-р, například přijde klient a zadá objednávku.
Označme podle r k pravděpodobnost, že událost nastane v tuto chvíli poprvé Na, těch. Na-Klient provedl objednávku a předchozí Na- 1 žádné klienty. Pak lze pravděpodobnost této komplexní události určit pomocí věty o násobení pravděpodobností nezávislých událostí
Pravděpodobnosti událostí s geometrickým rozložením jsou znázorněny na Obr. 11.2.
Součet pravděpodobností všech možných událostí
je geometrická posloupnost, proto se rozdělení nazývá geometrický. Od (1- p)

Náhodná proměnná Xs geometrické rozdělení má význam čísla prvního úspěšného testu v Bernoulliho schématu.

Rýže. 11.2.
Stanovme pravděpodobnost, že k události dojde X>k

a geometrické distribuční funkce

Vypočítejme generující funkci geometrického rozdělení pomocí (11.1) a (11.20)
matematické očekávání geometrického rozdělení podle (11.6)
a disperze podle (11.7)

Geometrické rozložení je považováno za diskrétní verzi spojitého exponenciálního rozložení a má také řadu vlastností užitečných pro modelování servisních systémů. Konkrétně, stejně jako exponenciální rozdělení, geometrické rozdělení nemá žádnou paměť:

těch. pokud byly provedeny / neúspěšné experimenty, pak je pravděpodobné, že pro první úspěch je nutné provést další j nových experimentů je stejná jako pravděpodobnost, že v nové sérii testů je pro první úspěch nutné provést./"experimenty. Jinými slovy, předchozí experimenty nemají žádný vliv na budoucí experimenty a zkušenosti jsou nezávislé. To je často pravda, například klienti jsou nezávislí a objednávky se dělají náhodně.
Uvažujme příklad systému, jehož provozní parametry se řídí geometrickým rozdělením.
Mistr má k dispozici n podobné náhradní díly. Každý detail je pravděpodobný q má defekt. Při opravě se díl instaluje do zařízení, u kterého se testuje funkčnost. Pokud zařízení nefunguje, je díl vyměněn za jiný. Vezmeme-li v úvahu náhodnou veličinu X- počet dílů ke kontrole.
Pravděpodobnosti počtu kontrolovaných dílů budou mít hodnoty uvedené v tabulce:
|
rya"~ x |
Zde q = 1 - r.
Matematické očekávání počtu kontrolovaných dílů je definováno jako

Binomické rozdělení. Zvažte náhodnou veličinu
Kde Xj se řídí Bernoulliho rozdělení s parametrem r a náhodné proměnné Xj nezávislý.
Hodnota náhodné proměnné X se bude rovnat počtu výskytů jednotek at n testy, tzn. náhodná veličina s binomickým rozdělením má význam počtu úspěchů v n nezávislé testy.
Podle (11.9) je generující funkce součtu vzájemně nezávislých náhodných veličin, z nichž každá má Bernoulliho rozdělení, rovna součinu jejich generujících funkcí (11.17):
Rozšířením generující funkce (11.26) v řadě získáme

V souladu s definicí generující funkce (11.1) je pravděpodobnost, že náhodná veličina X bude mít hodnotu Na:
Kde  - binomické koeficienty.
- binomické koeficienty.
11 kusů a jednotek na n místa lze uspořádat způsoby C*, pak počet vzorků obsahujících Na jednotky budou samozřejmě stejné.
Distribuční funkce pro binomický zákon se vypočítá pomocí vzorce
Distribuce se nazývá binomický vzhledem k tomu, že pravděpodobnosti ve formě jsou členy binomického rozvoje:

Je jasné, že celková pravděpodobnost všech možných výsledků je rovna 1:

Z (11.29) můžeme získat řadu užitečných vlastností binomických koeficientů. Například kdy r =1, q= 1 dostaneme
Pokud dáte r =1, q= - 1, tedy
Pro jakékoli 1k platí následující vztahy:
Pravděpodobnost, že v n testech, událost nastane: 1) méně než × 2) více Na jednou; 3) ne méně než × 4) ne více než ×, podle vzorců: 
Pomocí (11.6) určíme matematické očekávání binomického rozdělení
a podle (11.7) - disperze: 
Uvažujme několik příkladů systémů, jejichž provozní parametry jsou popsány binomickým rozdělením.
1. Šarže 10 výrobků obsahuje jeden nestandardní výrobek. Najděte pravděpodobnost, že na náhodném vzorku 5 produktů budou všechny standardní (event A).
Počet všech náhodných vzorků p - S, e 0 a počet vzorků příznivých pro událost je n= C95. Požadovaná pravděpodobnost je tedy rovna

2. Při nastěhování do nového bytu byly 2 zapnuty v síti osvětlení Na nové elektrické lampy. Každá elektrická lampa v průběhu roku s určitou pravděpodobností vyhoří r. Najděte pravděpodobnost, že do roka bude nutné vyměnit alespoň polovinu původně zapnutých žárovek za nové (příp. A):

3. Osoba patřící do určité skupiny spotřebitelů preferuje produkt 1 s pravděpodobností 0,2, produkt 2 s pravděpodobností 0,3, produkt 3 s pravděpodobností 0,4, produkt 4 s pravděpodobností 0,1. Pojďme zjistit pravděpodobnosti následujících událostí: A - skupina obsahuje alespoň 4 spotřebitele, kteří preferují produkt 3; V- skupina obsahuje alespoň jednoho spotřebitele, který preferuje produkt 4.
Tyto pravděpodobnosti jsou stejné:
Na svobodě/? Výpočty pravděpodobnosti se stávají těžkopádnými, proto se používají limitní věty.
Místní Laplaceova věta, podle kterého pravděpodobnost R p (k) je určeno vzorcem
Kde  - Gaussova funkce;
- Gaussova funkce; 
Laplaceova integrální věta se používá k výpočtu pravděpodobnosti, že n nezávislých testů událost nastane neméně Komu ( jednou a už ne do 2 jednou:
Podívejme se na příklady použití těchto teorémů.
1. Šicí dílna vyrábí oděvy na zakázku, které jsou z 90% té nejvyšší kvality. Najděte pravděpodobnost, že mezi 200 produkty bude minimálně 160 a maximálně 170 těch nejkvalitnějších.
Řešení: 
2. Pojišťovna má 12 tisíc klientů. Každý z nich, pojištění proti nehodě, přispívá 10 tisíc rublů. Pravděpodobnost nehody r - 0,006 a platba oběti je 1 milion rublů. Najdeme zisk pojišťovny, zajištěný s pravděpodobností 0,995; jinými slovy, jaký zisk může pojišťovna očekávat při úrovni rizika 0,005.
Řešení: Celkový příspěvek všech klientů je 12 000-10 000 = 120 milionů rublů. Zisk firmy závisí na čísle Na nehod a je určena rovností I = 120 000-1000/: tisíc rublů.
Proto potřebujeme najít číslo A/ takové, že pravděpodobnost události P(k > M) nepřesáhl 0,005. Pak bude s pravděpodobností 0,995 zajištěn zisk I = 120000-10004/ tisíc rublů.
Nerovnost P(k > M)Р(к0,995. Od do > 0, tedy P( 0 0,995. K odhadu této pravděpodobnosti použijeme Laplaceovu integrální větu p- 12 000 a/?=0,006, #=0,994:

Protože*! F(x]) = -0,5.
Je tedy nutné najít A/ pro které
najdeme (M- 72)/8,5 > 2,58. Proto, M>12 + 22 = 94.
Takže s pravděpodobností 0,995 společnost garantuje zisk
Často musíte určit nejpravděpodobnější číslo na 0. Pravděpodobnost výskytu události s počtem úspěchů na 0 přesahuje nebo alespoň ne méně než pravděpodobnost jiných možných výsledků testu. S největší pravděpodobností číslo na 0 určeno z dvojité nerovnosti
3. Nechť je 25 vzorků spotřebního zboží. Pravděpodobnost, že každý vzorek bude pro klienta přijatelný, je 0,7. Musí být stanoven nejpravděpodobnější počet vzorků, které budou přijatelné pro zákazníky. Po (11,39)

Odtud na 0 - 18.
Poissonovo rozdělení. Poissonovo rozdělení určuje pravděpodobnost, že při velkém počtu pokusů p, v každém z nich pravděpodobnost události r velmi malý, událost nastane přesně do schz.
Nechte pracovat pr = k; to znamená, že průměrný počet výskytů události v různých sériích pokusů, tzn. při různých p, zůstává beze změny. V tomto případě lze Poissonovo rozdělení použít k aproximaci binomického rozdělení:

Protože pro velké n 
Funkce generující Poissonovo rozdělení se vypočítá pomocí (11.1) jako
kde podle Maclaurinova vzorce
V souladu s vlastností koeficientů generující funkce pravděpodobnost výskytu Naúspěchy s průměrným počtem úspěchů X se vypočítá jako (11,40).
Na Obr. Obrázek 11.3 ukazuje Poissonovu funkci hustoty pravděpodobnosti.
Funkci generující Poissonovo rozdělení lze také získat použitím řady rozšíření generující funkce binomického rozdělení pro pr = X na n-» oo a Maclaurinův vzorec (11.42):

Rýže. 11.3.
Určíme matematické očekávání pomocí (11.6)
a disperze podle (11.7)

Uvažujme příklad systému s Poissonovým rozdělením parametrů.
Společnost zaslala do prodejny 500 produktů. Pravděpodobnost poškození produktu při přepravě je 0,002. Najděte pravděpodobnosti poškození produktů na cestě: přesně 3 (událost I); méně než 3 (udál V) více než 3 (událost Q; alespoň jedna (událost D).
Číslo n= 500 je vysoká pravděpodobnost r= 0,002 je málo, uvažované události (poškození výrobků) jsou nezávislé, lze tedy použít Poissonův vzorec (11,40).
Na X = pr = 500 0,002=1 dostaneme:

Poissonovo rozdělení má řadu vlastností užitečných pro modelování servisních systémů.
1. Součet náhodných veličin X = X ( + X 2 s Poissonovým rozdělením se také rozděluje podle Poissonova zákona.
Pokud mají náhodné proměnné generující funkce:
pak podle (11.9) bude mít generující funkce součtu nezávislých náhodných veličin s Poissonovým rozdělením tvar:
Výsledný distribuční parametr je roven X x + X 2.
2. Pokud se počet prvků./V množiny řídí Poissonovým rozdělením s parametrem X a každý prvek je vybrán nezávisle s pravděpodobností p, pak mají prvky vzorku velikost Y rozdělené podle Poissonova zákona s parametrem rH.
Nechat ![]() , Kde
, Kde ![]() odpovídá Bernoulliho distribuci a N- Poissonovo rozdělení. Odpovídající generující funkce podle (11.17), (11.41):
odpovídá Bernoulliho distribuci a N- Poissonovo rozdělení. Odpovídající generující funkce podle (11.17), (11.41):
Generující funkce náhodné veličiny Y vypočteno v souladu s (11.14)
těch. generující funkce odpovídá Poissonovu rozdělení s parametrem rH.
3. V důsledku vlastnosti 2 platí následující vlastnost. Pokud je počet prvků množiny rozdělen podle Poissonova zákona s parametrem X a množina je náhodně rozdělena s pravděpodobnostmi /?, a p 2 = 1 - R do dvou skupin, pak jsou velikosti sad 7V, a N 2 nezávislé a Poissonovo distribuované s parametry p(k A r(k.
Pro usnadnění použití uvádíme výsledky získané ohledně diskrétních rozdělení ve formě tabulky. 11.1 a 11.2.
Tabulka 11.1. Hlavní charakteristiky diskrétních rozdělení
|
Rozdělení |
Hustota |
Rozsah |
Možnosti |
tn | |
C X--2 |
|
|
Bernoulli |
Р(Х = ) = р Р (X = 0} = R + I= 1 |
p - 0,1 |
||||
|
Geometrický |
p(-p) k-1 |
k = 1,2,... |
^ 1 1 |tz |
1 -r |
||
|
Binomický |
s k r k (- R g k |
* = 1,2,...,#" |
pr( - r) |
1 -r pr |
||
|
Poisson |
E Na! |
k = 1,2,... |
Tabulka 11. 2. Generující funkce diskrétních rozdělení
TESTOVACÍ OTÁZKY
- 1. Jaká rozdělení pravděpodobnosti jsou považována za diskrétní?
- 2. Co je to generující funkce a k čemu slouží?
- 3. Jak vypočítat momenty náhodných veličin pomocí generující funkce?
- 4. Jaká je generující funkce součtu nezávislých náhodných veličin?
- 5. Co se nazývá složené rozdělení a jak se počítají generující funkce složených rozdělení?
- 6. Uveďte hlavní charakteristiky Bernoulliho rozvodu, uveďte příklad použití v servisních úkolech.
- 7. Uveďte hlavní charakteristiky geometrického rozdělení, uveďte příklad použití v servisních úlohách.
- 8. Uveďte hlavní charakteristiky binomického rozdělení, uveďte příklad jeho použití v servisních úlohách.
- 9. Uveďte hlavní charakteristiky Poissonova rozdělení, uveďte příklad použití v obslužných problémech.
Kapitola 1. Diskrétní náhodná veličina
§ 1. Pojmy náhodné veličiny.
Zákon rozdělení diskrétní náhodné veličiny.
Definice : Náhodná je veličina, která v důsledku testování odebírá pouze jednu hodnotu z možné množiny svých hodnot, předem neznámou a závislou na náhodných důvodech.
Existují dva typy náhodných proměnných: diskrétní a spojité.
Definice : Volá se náhodná proměnná X diskrétní (nespojitý), pokud je množina jeho hodnot konečná nebo nekonečná, ale spočetná.
Jinými slovy, možné hodnoty diskrétní náhodné proměnné lze přečíslovat.
Náhodná veličina může být popsána pomocí jejího distribučního zákona.
Definice : Distribuční zákon diskrétní náhodné veličiny nazvěte korespondenci mezi možnými hodnotami náhodné veličiny a jejich pravděpodobnostmi.
Distribuční zákon diskrétní náhodné veličiny X lze specifikovat ve formě tabulky, v jejímž prvním řádku jsou vzestupně uvedeny všechny možné hodnoty náhodné veličiny a ve druhém řádku odpovídající pravděpodobnosti těchto veličin. hodnoty, tzn.
kde р1+ р2+…+ рn=1
Taková tabulka se nazývá distribuční řada diskrétní náhodné veličiny.
Pokud je množina možných hodnot náhodné veličiny nekonečná, pak řada p1+ p2+…+ pn+… konverguje a její součet je roven 1.
Distribuční zákon diskrétní náhodné veličiny X lze znázornit graficky, pro kterou je v pravoúhlém souřadnicovém systému sestrojena přerušovaná čára spojující postupně body se souřadnicemi (xi; pi), i=1,2,…n. Výsledný řádek se nazývá distribuční polygon (obr. 1).
Organická chemie" href="/text/category/organicheskaya_hiimya/" rel="bookmark">organická chemie je 0,7 a 0,8. Sestavte distribuční zákon pro náhodnou veličinu X - počet zkoušek, které student složí.
Řešení. Uvažovaná náhodná veličina X jako výsledek zkoušky může nabývat jedné z následujících hodnot: x1=0, x2=1, x3=2.
Najděte pravděpodobnost těchto hodnot.
https://pandia.ru/text/78/455/images/image004_81.jpg" width="259" height="66 src=">
 |
Takže distribuční zákon náhodné veličiny X je dán tabulkou:
Kontrola: 0,6+0,38+0,56=1.
§ 2. Distribuční funkce
Úplný popis náhodné veličiny poskytuje také distribuční funkce.
Definice: Distribuční funkce diskrétní náhodné veličiny X se nazývá funkce F(x), která pro každou hodnotu x určuje pravděpodobnost, že náhodná veličina X nabude hodnoty menší než x:
F(x)=P(X<х)
Geometricky je distribuční funkce interpretována jako pravděpodobnost, že náhodná veličina X nabude hodnoty, která je na číselné ose reprezentována bodem ležícím vlevo od bodu x.
1)0 2) F(x) je neklesající funkce na (-∞;+∞); 3) F(x) - spojitá zleva v bodech x= xi (i=1,2,...n) a spojitá ve všech ostatních bodech; 4) F(-∞)=P (X<-∞)=0 как вероятность невозможного события Х<-∞, F(+∞)=P(X<+∞)=1 как вероятность достоверного события Х<-∞. Pokud je distribuční zákon diskrétní náhodné veličiny X dán ve formě tabulky: pak distribuční funkce F(x) je určena vzorcem: https://pandia.ru/text/78/455/images/image007_76.gif" height="110"> 0 pro x≤ x1, р1 na x1< х≤ x2, F(x)= р1 + р2 v x2< х≤ х3 1 pro x>xn. Jeho graf je na obr. 2: §
3. Numerické charakteristiky diskrétní náhodné veličiny. Jednou z důležitých číselných charakteristik je matematické očekávání. Definice: Matematické očekávání M(X)
diskrétní náhodná veličina X je součtem součinů všech jejích hodnot a jejich odpovídajících pravděpodobností: M(X) =
∑ xiрi= x1р1 + x2р2+…+ xnрn Matematické očekávání slouží jako charakteristika průměrné hodnoty náhodné veličiny. Vlastnosti matematického očekávání:
1)M(C)=C, kde C je konstantní hodnota; 2)M(CX)=CM(X), 3) M(X±Y)=M(X)+M(Y); 4)M(XY)=M(X) M(Y), kde X, Y jsou nezávislé náhodné proměnné; 5) M(X±C)=M(X)±C, kde C je konstantní hodnota; Pro charakterizaci stupně disperze možných hodnot diskrétní náhodné proměnné kolem její střední hodnoty se používá disperze. Definice:
Rozptyl
D
(
X
)
náhodná veličina X je matematické očekávání druhé mocniny odchylky náhodné veličiny od jejího matematického očekávání:
Vlastnosti disperze:
1)D(C)=0, kde C je konstantní hodnota; 2)D(X)>0, kde X je náhodná veličina; 3)D(CX)=C2D(X), kde C je konstantní hodnota; 4)D(X+Y)=D(X)+D(Y), kde X, Y jsou nezávislé náhodné proměnné; Pro výpočet rozptylu je často vhodné použít vzorec: D(X)=M(X2)-(M(X))2, kde M(X)=∑ xi2рi= x12р1 + x22р2+…+ xn2рn Rozptyl D(X) má rozměr druhé mocniny náhodné veličiny, což není vždy vhodné. Proto se hodnota √D(X) používá také jako indikátor rozptylu možných hodnot náhodné veličiny. Definice: Směrodatná odchylka σ(X)
náhodná proměnná X se nazývá druhá odmocnina rozptylu: Úkol č. 2. Diskrétní náhodná veličina X je určena distribučním zákonem: Najděte P2, distribuční funkci F(x) a nakreslete její graf, stejně jako M(X), D(X), σ(X). Řešení:
Protože součet pravděpodobností možných hodnot náhodné veličiny X je roven 1, pak Р2=1- (0,1+0,3+0,2+0,3)=0,1 Pojďme najít distribuční funkci F(x)=P(X Geometricky lze tuto rovnost interpretovat následovně: F(x) je pravděpodobnost, že náhodná veličina nabude hodnotu, která je na číselné ose znázorněna bodem ležícím vlevo od bodu x. Jestliže x≤-1, pak F(x)=0, protože na (-∞;x) není jediná hodnota této náhodné veličiny; Pokud -1<х≤0, то F(х)=Р(Х=-1)=0,1, т. к. в промежуток (-∞;х) попадает только одно значение x1=-1; Pokud 0<х≤1, то F(х)=Р(Х=-1)+ Р(Х=0)=0,1+0,1=0,2, т. к. в промежуток (-∞;x) existují dvě hodnoty x1=-1 a x2=0; Pokud 1<х≤2, то F(х)=Р(Х=-1) + Р(Х=0)+ Р(Х=1)= 0,1+0,1+0,3=0,5, т. к. в промежуток (-∞;х) попадают три значения x1=-1, x2=0 и x3=1; Pokud 2<х≤3, то F(х)=Р(Х=-1) + Р(Х=0)+ Р(Х=1)+ Р(Х=2)= 0,1+0,1+0,3+0,2=0,7, т. к. в промежуток (-∞;х) попадают четыре значения x1=-1, x2=0,x3=1 и х4=2; Pokud x>3, pak F(x)=P(X=-1) + P(X=0)+ P(X=1)+ P(X=2)+P(X=3)= 0,1 +0,1 +0,3+0,2+0,3=1, protože čtyři hodnoty x1=-1, x2=0, x3=1, x4=2 spadají do intervalu (-∞;x) a x5=3. https://pandia.ru/text/78/455/images/image006_89.gif" width="14 height=2" height="2"> 0 na x≤-1, 0,1 při -1<х≤0, 0,2 na 0<х≤1, F(x)= 0,5 při 1<х≤2, 0,7 ve 2<х≤3, 1 na x>3 Znázorněme funkci F(x) graficky (obr. 3): https://pandia.ru/text/78/455/images/image014_24.jpg" width="158 height=29" height="29">≈1,2845. §
4. Zákon binomického rozdělení diskrétní náhodná veličina, Poissonův zákon. Definice: Binomický
se nazývá zákon rozdělení diskrétní náhodné veličiny X - počet výskytů jevu A v n nezávislých opakovaných pokusech, v každém z nich může událost A nastat s pravděpodobností p nebo nenastat s pravděpodobností q = 1-p. Pak P(X=m) - pravděpodobnost výskytu události A přesně mkrát v n pokusech se vypočítá pomocí Bernoulliho vzorce: Р(Х=m)=Сmnpmqn-m Matematické očekávání, rozptyl a směrodatná odchylka náhodné veličiny X rozdělené podle binárního zákona se nalézají pomocí vzorců: https://pandia.ru/text/78/455/images/image016_31.gif" width="26"> Pravděpodobnost události A – „vypuštění pětky“ v každém pokusu je stejná a rovná se 1/6 , tj. P(A)=p=1/6, pak P(A)=l-p=q=5/6, kde - "neschopnost získat A." Náhodná veličina X může nabývat následujících hodnot: 0;1;2;3. Pravděpodobnost každé z možných hodnot X zjistíme pomocí Bernoulliho vzorce: Р(Х=0)=Р3(0)=С03р0q3=1 (1/6)0 (5/6)3=125/216; Р(Х=1)=Р3(1)=С13р1q2=3 (1/6)1 (5/6)2=75/216; Р(Х=2)=Р3(2)=С23р2q=3 (1/6)2 (5/6)1=15/216; Р(Х=3)=Р3(3)=С33р3q0=1 (1/6)3 (5/6)0=1/216. Že. distribuční zákon náhodné veličiny X má tvar: Kontrola: 125/216+75/216+15/216+1/216=1. Pojďme najít číselné charakteristiky náhodné veličiny X: M(X)=np=3 (1/6)=1/2, D(X)=npq=3 (1/6) (5/6)=5/12, Úkol č. 4. Automat razí díly. Pravděpodobnost, že vyrobený díl bude vadný, je 0,002. Najděte pravděpodobnost, že mezi 1000 vybranými díly bude: a) 5 vadných; b) alespoň jeden je vadný. Řešení:
Číslo n=1000 je velké, pravděpodobnost výroby vadného dílu p=0,002 je malá a uvažované události (součást se ukáže jako vadná) jsou nezávislé, proto platí Poissonův vzorec: Рn(m)= E-
λ
λm Nalezneme λ=np=1000 0,002=2. a) Najděte pravděpodobnost, že bude 5 vadných dílů (m=5): Р1000(5)= E-2
25
= 32 0,13534
= 0,0361 b) Najděte pravděpodobnost, že bude alespoň jeden vadný díl. Událost A – „alespoň jeden z vybraných dílů je vadný“ je opakem události – „všechny vybrané díly nejsou vadné“, tedy P(A) = 1-P(). Požadovaná pravděpodobnost je tedy rovna: P(A)=1-P1000(0)=1- E-2
20
= 1- e-2=1-0,13534≈0,865. Úkoly pro samostatnou práci.
1.1
1.2.
Dispergovaná náhodná veličina X je určena distribučním zákonem: Najděte p4, distribuční funkci F(X) a vykreslete její graf, stejně jako M(X), D(X), σ(X). 1.3.
V krabičce je 9 fixů, z nichž 2 již nepíší. Náhodně vezměte 3 značky. Náhodná proměnná X je počet zapsaných značek mezi těmi, které byly odebrány. Sestavte zákon rozdělení náhodné veličiny. 1.4.
Na polici knihovny je náhodně rozmístěno 6 učebnic, z toho 4 svázané. Knihovník si náhodně vezme 4 učebnice. Náhodná veličina X je počet svázaných učebnic mezi převzatými. Sestavte zákon rozdělení náhodné veličiny. 1.5.
Na lístku jsou dva úkoly. Pravděpodobnost správného vyřešení prvního problému je 0,9, druhého 0,7. Náhodná veličina X je počet správně vyřešených problémů v tiketu. Sestavte distribuční zákon, vypočítejte matematické očekávání a rozptyl této náhodné veličiny a také najděte distribuční funkci F(x) a sestavte její graf. 1.6.
Tři střelci střílejí na terč. Pravděpodobnost zasažení cíle jednou ranou je 0,5 pro prvního střelce, 0,8 pro druhého a 0,7 pro třetího. Náhodná proměnná X je počet zásahů do terče, pokud střelci vystřelí po jedné střele. Najděte zákon rozdělení, M(X),D(X). 1.7.
Basketbalista střílí míč do koše s pravděpodobností, že trefí každou ránu 0,8. Za každý zásah dostává 10 bodů a pokud netrefí, body mu nejsou přiděleny. Sestavte distribuční zákon pro náhodnou veličinu X - počet bodů, které basketbalista obdrží za 3 rány. Najděte M(X),D(X) a také pravděpodobnost, že získá více než 10 bodů. 1.8.
Na kartičkách jsou napsána písmena, celkem 5 samohlásek a 3 souhlásky. Náhodně se vyberou 3 karty a pokaždé se odebraná karta vrátí zpět. Náhodná proměnná X je počet samohlásek mezi převzatými. Sestavte distribuční zákon a najděte M(X),D(X),σ(X). 1.9.
V průměru pod 60 % smluv pojišťovna vyplácí pojistné částky v souvislosti se vznikem pojistné události. Vypracujte zákon o rozdělení pro náhodnou veličinu X - počet smluv, za které byla vyplacena pojistná částka, mezi čtyři náhodně vybrané smlouvy. Najděte číselné charakteristiky této veličiny. 1.10.
Radiostanice vysílá volací značky (ne více než čtyři) v určitých intervalech, dokud není navázána obousměrná komunikace. Pravděpodobnost přijetí odpovědi na volací znak je 0,3. Náhodná proměnná X je počet odeslaných volacích znaků. Sestavte zákon o rozdělení a najděte F(x). 1.11.
K dispozici jsou 3 klíče, z nichž pouze jeden pasuje do zámku. Sestavte zákon pro rozdělení náhodné veličiny X-počet pokusů o otevření zámku, pokud se vyzkoušený klíč nezúčastní následujících pokusů. Najděte M(X),D(X). 1.12.
Provádějí se po sobě jdoucí nezávislé testy spolehlivosti tří zařízení. Každé následující zařízení je testováno pouze v případě, že se předchozí ukázalo jako spolehlivé. Pravděpodobnost úspěšného složení testu pro každé zařízení je 0,9. Sestavte distribuční zákon pro náhodnou veličinu X-počet testovaných zařízení. 1.13
.Diskrétní náhodná proměnná X má tři možné hodnoty: x1=1, x2, x3 a x1<х2<х3. Вероятность того, что Х примет значения х1 и х2, соответственно равны 0,3 и 0,2. Известно, что М(Х)=2,2, D(X)=0,76. Составить закон распределения случайной величины. 1.14.
Blok elektronického zařízení obsahuje 100 stejných prvků. Pravděpodobnost selhání každého prvku během času T je 0,002. Prvky fungují samostatně. Najděte pravděpodobnost, že během času T selžou maximálně dva prvky. 1.15.
Učebnice vyšla v nákladu 50 000 výtisků. Pravděpodobnost, že je učebnice svázána špatně, je 0,0002. Najděte pravděpodobnost, že oběh obsahuje: a) čtyři vadné knihy, b) méně než dvě vadné knihy. 1
.16.
Počet hovorů přicházejících na ústřednu každou minutu je rozdělen podle Poissonova zákona s parametrem λ=1,5. Najděte pravděpodobnost, že za minutu přijde následující: a) dvě výzvy; b) alespoň jeden hovor. 1.17.
Najděte M(Z),D(Z), pokud Z=3X+Y. 1.18.
Jsou dány zákony rozdělení dvou nezávislých náhodných veličin: Najděte M(Z),D(Z), pokud Z=X+2Y. Odpovědi:
https://pandia.ru/text/78/455/images/image007_76.gif" height="110"> 1.1.
p3 = 0,4; 0 při x≤-2, 0,3 při -2<х≤0, F(x)= 0,5 při 0<х≤2, 0,9 ve 2<х≤5, 1 při x>5 0,3 při -1<х≤0, 0,4 na 0<х≤1, F(x)= 0,6 při 1<х≤2, 0,7 ve 2<х≤3, 1 na x>3 M(X) = 1; D(X) = 2,6; σ(X) ≈1,612. https://pandia.ru/text/78/455/images/image025_24.gif" width="2 height=98" height="98"> 0 při x≤0, 0,03 na 0<х≤1, F(x)= 0,37 při 1<х≤2, 1 pro x>2 M(X) = 2; D(X) = 0,62 M(X) = 2,4; D(X)=0,48, P(X>10)=0,896 1.
8
.
M(X) = 15/8; D(X) = 45/64; σ(Х) ≈ M(X) = 2,4; D(X) = 0,96 https://pandia.ru/text/78/455/images/image008_71.gif" width="14"> 1.11.
M(X) = 2; D(X) = 2/3 1.14.
1,22 e-0,2≈0,999 1.15.
a)0,0189; b) 0,00049 1.16.
a)0,0702; b)0,77687 1.17.
3,8; 14,2 1.18.
11,2; 4. Kapitola 2. Spojitá náhodná veličina
Definice: Kontinuální
Volají množství všech možných hodnot, které zcela vyplňují konečný nebo nekonečný rozsah číselné osy. Je zřejmé, že počet možných hodnot spojité náhodné proměnné je nekonečný. Spojitou náhodnou veličinu lze zadat pomocí distribuční funkce. Definice: F distribuční funkce
spojitá náhodná proměnná X se nazývá funkce F(x), která pro každou hodnotu určuje xhttps://pandia.ru/text/78/455/images/image028_11.jpg" width="14" height="13"> R Distribuční funkce se někdy nazývá kumulativní distribuční funkce. Vlastnosti distribuční funkce:
1)1≤ F(x) ≤1 2) Pro spojitou náhodnou veličinu je distribuční funkce spojitá v libovolném bodě a diferencovatelná všude, snad kromě jednotlivých bodů. 3) Pravděpodobnost, že náhodná veličina X spadne do jednoho z intervalů (a;b), [a;b], [a;b], je rovna rozdílu mezi hodnotami funkce F(x) v bodech a a b, tzn. R(a)<Х 4) Pravděpodobnost, že spojitá náhodná veličina X bude mít jednu samostatnou hodnotu, je 0. 5) F(-∞)=0, F(+∞)=1 Zadání spojité náhodné proměnné pomocí distribuční funkce není jediný způsob. Zaveďme pojem hustota rozdělení pravděpodobnosti (hustota rozdělení). Definice
:
Hustota rozdělení pravděpodobnosti
F
(
x
)
spojité náhodné veličiny X je derivace její distribuční funkce, tj. Funkce hustoty pravděpodobnosti se někdy nazývá diferenciální distribuční funkce nebo zákon diferenciálního rozdělení. Zavolá se graf rozdělení hustoty pravděpodobnosti f(x). křivka rozdělení pravděpodobnosti
.
Vlastnosti rozdělení hustoty pravděpodobnosti:
1) f(x) ≥0, na adrese xhttps://pandia.ru/text/78/455/images/image029_10.jpg" width="285" height="141">.gif" width="14" height ="62 src="> 0 na x≤2, f(x)= c(x-2) na 2<х≤6, 0 pro x>6. Najděte: a) hodnotu c; b) distribuční funkci F(x) a vykreslete ji; c) P(3≤x<5) Řešení:
+
∞ a) Z normalizační podmínky zjistíme hodnotu c: ∫ f(x)dx=1. Proto -∞ https://pandia.ru/text/78/455/images/image032_23.gif" height="38 src="> -∞ 2 2 x pokud 2<х≤6, то F(x)= ∫ 0dx+∫ 1/8(х-2)dx=1/8(х2/2-2х) = 1/8(х2/2-2х - (4/2-4))= 1/8(x2/2-2x+2)=1/16(x-2)2; Gif" width="14" height="62"> 0 v x≤2, F(x)= (x-2)2/16 na 2<х≤6, 1 pro x>6. Graf funkce F(x) je na obr. 3. Obr https://pandia.ru/text/78/455/images/image034_23.gif" width="14" height="62 src="> 0 na x≤0, F(x)= (3 arctan x)/π při 0<х≤√3, 1 pro x>√3. Najděte diferenciální distribuční funkci f(x) Řešení:
Protože f(x)= F'(x), tak https://pandia.ru/text/78/455/images/image011_36.jpg" width="118" height="24"> Všechny vlastnosti matematického očekávání a disperze, diskutované dříve pro rozptýlené náhodné veličiny, jsou platné i pro spojité. Úkol č. 3. Náhodná veličina X je určena diferenciální funkcí f(x): https://pandia.ru/text/78/455/images/image036_19.gif" height="38"> -∞ 2 X3/9 + x2/6 = 8/9-0+9/6-4/6=31/18, https://pandia.ru/text/78/455/images/image032_23.gif" height="38"> +∞ D(X)= ∫ x2 f(x)dx-(M(x))2=∫ x2 x/3 dx+∫1/3x2 dx=(31/18)2=x4/12 + x3/9 - - (31/18)2=16/12-0+27/9-8/9-(31/18)2=31/9- (31/18)2==31/9(1-31/36)=155/324, https://pandia.ru/text/78/455/images/image032_23.gif" height="38"> P(1<х<5)= ∫ f(x)dx=∫ х/3 dx+∫ 1/3 dx+∫ 0 dx= х2/6 +1/3х = 4/6-1/6+1-2/3=5/6. Problémy k samostatnému řešení.
2.1.
Spojitá náhodná veličina X je určena distribuční funkcí: 0 při x≤0, F(x)= https://pandia.ru/text/78/455/images/image038_17.gif" width="14" height="86"> 0 pro x≤ π/6, F(x)= - cos 3x při π/6<х≤ π/3, 1 pro x> π/3. Najděte diferenciální distribuční funkci f(x) a také Р(2π /9<Х< π /2). 2.3.
0 při x≤2, f(x)= c x na 2<х≤4, 0 pro x>4. 2.4.
Spojitá náhodná veličina X je určena hustotou distribuce: 0 při x≤0, f(x)= c √x při 0<х≤1, 0 pro x>1. Najděte: a) číslo c; b) M(X), D(X). 2.5.
https://pandia.ru/text/78/455/images/image041_3.jpg" width="36" height="39"> na x, 0 v x. Najděte: a) F(x) a vykreslete to; b) M(X), D(X), a(X); c) pravděpodobnost, že ve čtyřech nezávislých pokusech bude hodnota X nabývat přesně dvojnásobku hodnoty patřící do intervalu (1;4). 2.6.
Hustota rozdělení pravděpodobnosti spojité náhodné veličiny X je dána: f(x)= 2(x-2) v x, 0 v x. Najděte: a) F(x) a vykreslete to; b) M(X), D(X), a (X); c) pravděpodobnost, že ve třech nezávislých pokusech bude hodnota X nabývat přesně dvojnásobku hodnoty patřící segmentu . 2.7.
Funkce f(x) je dána jako: https://pandia.ru/text/78/455/images/image045_4.jpg" width="43" height="38 src=">.jpg" width="16" height="15">[-√ 3/2; √3/2]. 2.8.
Funkce f(x) je dána jako: https://pandia.ru/text/78/455/images/image046_5.jpg" width="45" height="36 src="> .jpg" width="16" height="15">[- π /4; π /4]. Najděte: a) hodnotu konstanty c, při které bude funkce hustotou pravděpodobnosti nějaké náhodné veličiny X; b) distribuční funkce F(x). 2.9.
Náhodná veličina X, soustředěná na interval (3;7), je specifikována distribuční funkcí F(x)= . Najděte pravděpodobnost, že náhodná veličina X bude mít hodnotu: a) menší než 5, b) ne menší než 7. 2.10.
Náhodná veličina X, soustředěná na interval (-1;4), je dáno distribuční funkcí F(x)= . Najděte pravděpodobnost, že náhodná veličina X bude mít hodnotu: a) menší než 2, b) ne menší než 4. 2.11.
https://pandia.ru/text/78/455/images/image049_6.jpg" width="43" height="44 src="> .jpg" width="16" height="15">. Najděte: a) číslo c; b) M(X); c) pravděpodobnost P(X> M(X)). 2.12.
Náhodná veličina je určena diferenciální distribuční funkcí: https://pandia.ru/text/78/455/images/image050_3.jpg" width="60" height="38 src=">.jpg" width="16 height=15" height="15"> . Najděte: a) M(X); b) pravděpodobnost P(X≤M(X)) 2.13.
Removo rozdělení je dáno hustotou pravděpodobnosti: https://pandia.ru/text/78/455/images/image052_5.jpg" width="46" height="37"> pro x ≥0. Dokažte, že f(x) je skutečně funkce hustoty pravděpodobnosti. 2.14.
Hustota rozdělení pravděpodobnosti spojité náhodné veličiny X je dána: https://pandia.ru/text/78/455/images/image054_3.jpg" width="174" height="136 src="> (obr. 4) 2.16.
Náhodná veličina X je rozdělena podle zákona „pravoúhlého trojúhelníku“ v intervalu (0;4) (obr. 5). Najděte analytický výraz pro hustotu pravděpodobnosti f(x) na celé číselné ose. Odpovědi
0 při x≤0, f(x)= https://pandia.ru/text/78/455/images/image038_17.gif" width="14" height="86"> 0 pro x≤ π/6, F(x)= 3sin 3x při π/6<х≤ π/3, 0 pro x> π/3. Spojitá náhodná veličina X má zákon rovnoměrného rozdělení na určitém intervalu (a;b), do kterého patří všechny možné hodnoty X, pokud je hustota rozdělení pravděpodobnosti f(x) na tomto intervalu konstantní a rovna 0 mimo to, tzn. 0 pro x≤a, f(x)= pro a<х 0 pro x≥b. Graf funkce f(x) je na Obr. 1 F(x)= https://pandia.ru/text/78/455/images/image077_3.jpg" width="30" height="37">, D(X)=, σ(X)=. Úkol č. 1. Náhodná veličina X je na segmentu rovnoměrně rozložena. Nalézt: a) hustotu rozdělení pravděpodobnosti f(x) a vykreslete ji; b) distribuční funkci F(x) a vykreslete ji; c) M(X), D(X), a(X). Řešení:
Pomocí výše uvedených vzorců s a=3, b=7 zjistíme: https://pandia.ru/text/78/455/images/image081_2.jpg" width="22" height="39"> ve 3≤х≤7, 0 pro x>7 Sestavme jeho graf (obr. 3): https://pandia.ru/text/78/455/images/image038_17.gif" width="14" height="86 src="> 0 na x≤3, F(x)= https://pandia.ru/text/78/455/images/image084_3.jpg" width="203" height="119 src=">Obr. 4 D(X) = ==https://pandia.ru/text/78/455/images/image089_1.jpg" width="37" height="43">==https://pandia.ru/text/ 78/455/images/image092_10.gif" width="14" height="49 src="> 0 na x<0, f(x)= λе-λх pro x≥0. Distribuční funkce náhodné veličiny X, rozdělené podle exponenciálního zákona, je dána vzorcem: https://pandia.ru/text/78/455/images/image094_4.jpg" width="191" height="126 src=">fig..jpg" width="22" height="30"> , D(X)=, σ (Х)= Matematické očekávání a směrodatná odchylka exponenciálního rozdělení se tedy navzájem rovnají. Pravděpodobnost, že X spadne do intervalu (a;b) se vypočítá podle vzorce: P(a<Х Úkol č. 2. Průměrná doba bezporuchového provozu zařízení je 100 hodin Za předpokladu, že doba bezporuchového provozu zařízení má exponenciální distribuční zákon, zjistěte: a) hustota rozdělení pravděpodobnosti; b) distribuční funkce; c) pravděpodobnost, že doba bezporuchového provozu zařízení přesáhne 120 hodin. Řešení:
Podle podmínky je matematické rozdělení M(X)=https://pandia.ru/text/78/455/images/image098_10.gif" height="43 src="> 0 na x<0, a) f(x)= 0,01e -0,01x pro x≥0. b) F(x)= 0 v x<0, 1-e -0,01x při x≥0. c) Požadovanou pravděpodobnost najdeme pomocí distribuční funkce: P(X>120)=1-F(120)=1-(1-e-1,2)= e-1,2≈0,3. §
3.Zákon normálního rozdělení Definice:
Spojitá náhodná veličina X má zákon normálního rozdělení (Gaussův zákon),
pokud má hustota distribuce tvar: kde m=M(X), a2=D(X), a>0. Křivka normálního rozdělení se nazývá normální nebo Gaussova křivka
(obr.7) Distribuční funkce náhodné veličiny X, rozdělené podle normálního zákona, je vyjádřena pomocí Laplaceovy funkce Ф (x) podle vzorce: kde je Laplaceova funkce. Komentář:
Funkce Ф(x) je lichá (Ф(-х)=-Ф(х)), navíc pro x>5 můžeme předpokládat Ф(х) ≈1/2. Graf distribuční funkce F(x) je na Obr. 8 https://pandia.ru/text/78/455/images/image106_4.jpg" width="218" height="33"> Pravděpodobnost, že absolutní hodnota odchylky je menší než kladné číslo δ, se vypočítá podle vzorce: Konkrétně pro m=0 platí následující rovnost: "Pravidlo tří sigma"
Pokud má náhodná veličina X zákon normálního rozdělení s parametry m a σ, pak je téměř jisté, že její hodnota leží v intervalu (a-3σ; a+3σ), protože https://pandia.ru/text/78/455/images/image110_2.jpg" width="157" height="57 src=">a) b) Použijeme vzorec: https://pandia.ru/text/78/455/images/image112_2.jpg" width="369" height="38 src="> Z tabulky funkčních hodnot Ф(х) najdeme Ф(1.5)=0.4332, Ф(1)=0.3413. Takže požadovaná pravděpodobnost: P(28 Úkoly pro samostatnou práci
3.1.
Náhodná veličina X je rovnoměrně rozložena v intervalu (-3;5). Nalézt: b) distribuční funkce F(x); c) číselné charakteristiky; d) pravděpodobnost P(4<х<6). 3.2.
Náhodná veličina X je na segmentu rovnoměrně rozložena. Nalézt: a) hustota distribuce f(x); b) distribuční funkce F(x); c) číselné charakteristiky; d) pravděpodobnost P(3≤х≤6). 3.3.
Na dálnici je automatický semafor, ve kterém svítí zelené světlo 2 minuty, žluté 3 sekundy, červené 30 sekund atd. Po dálnici jede auto v náhodný okamžik. Najděte pravděpodobnost, že auto projede semaforem, aniž by zastavilo. 3.4.
Vlaky metra jezdí pravidelně v intervalu 2 minut. Cestující vstoupí na nástupiště v náhodnou dobu. Jaká je pravděpodobnost, že cestující bude muset čekat na vlak déle než 50 sekund? Najděte matematické očekávání náhodné veličiny X - doba čekání na vlak. 3.5.
Najděte rozptyl a směrodatnou odchylku exponenciálního rozdělení dané distribuční funkcí: F(x)= 0 v x<0, 1.-8x pro x≥0. 3.6.
Spojitá náhodná veličina X je určena hustotou rozdělení pravděpodobnosti: f(x)= 0 v x<0, 0,7 e-0,7x při x≥0. a) Pojmenujte zákon rozdělení uvažované náhodné veličiny. b) Najděte distribuční funkci F(X) a číselné charakteristiky náhodné veličiny X. 3.7.
Náhodná veličina X je rozdělena podle exponenciálního zákona určeného hustotou rozdělení pravděpodobnosti: f(x)= 0 v x<0, 0,4 e-0,4 x při x≥0. Najděte pravděpodobnost, že jako výsledek testu bude X nabývat hodnoty z intervalu (2,5;5). 3.8.
Spojitá náhodná veličina X je distribuována podle exponenciálního zákona určeného distribuční funkcí: F(x)= 0 v x<0, 1.-0,6x při x≥0 Najděte pravděpodobnost, že v důsledku testu X převezme hodnotu ze segmentu. 3.9.
Očekávaná hodnota a směrodatná odchylka normálně rozdělené náhodné veličiny jsou 8 a 2, v tomto pořadí. a) hustota distribuce f(x); b) pravděpodobnost, že v důsledku testu X nabude hodnoty z intervalu (10;14). 3.10.
Náhodná veličina X je normálně rozdělena s matematickým očekáváním 3,5 a rozptylem 0,04. Nalézt: a) hustota distribuce f(x); b) pravděpodobnost, že v důsledku testu X nabude hodnotu ze segmentu . 3.11.
Náhodná veličina X je normálně rozdělena s M(X)=0 a D(X)=1. Která z událostí: |X|≤0,6 nebo |X|≥0,6 je pravděpodobnější? 3.12.
Náhodná veličina X je rozložena normálně s M(X)=0 a D(X)=1 Z jakého intervalu (-0,5;-0,1) nebo (1;2) je pravděpodobnější, že nabude hodnoty během jednoho testu? 3.13.
Aktuální cenu za akcii lze modelovat pomocí zákona normální distribuce s M(X)=10 den. jednotky a a (X) = 0,3 den. jednotky Nalézt: a) pravděpodobnost, že aktuální cena akcie bude od 9,8 den. jednotky až 10,4 dne jednotky; b) pomocí „pravidla tří sigma“ najděte hranice, ve kterých se bude nacházet aktuální cena akcií. 3.14.
Látka je zvážena bez systematických chyb. Náhodné chyby vážení podléhají normálnímu zákonu se středním čtvercovým poměrem σ=5g. Najděte pravděpodobnost, že ve čtyřech nezávislých experimentech nedojde k chybě ve třech vážení v absolutní hodnotě 3r. 3.15.
Náhodná veličina X je normálně rozdělena s M(X)=12,6. Pravděpodobnost, že náhodná veličina spadne do intervalu (11,4;13,8) je 0,6826. Najděte směrodatnou odchylku σ. 3.16.
Náhodná veličina X je rozdělena normálně s M(X)=12 a D(X)=36 Najděte interval, do kterého náhodná veličina X spadne jako výsledek testu s pravděpodobností 0,9973. 3.17.
Díl vyrobený automatickým strojem je považován za vadný, pokud odchylka X jeho řízeného parametru od jmenovité hodnoty překročí modulo 2 měrné jednotky. Předpokládá se, že náhodná veličina X je normálně rozdělena s M(X)=0 a σ(X)=0,7. Jaké procento vadných dílů stroj vyrábí? 3.18.
Parametr X součásti je rozložen normálně s matematickým očekáváním 2 rovným nominální hodnotě a směrodatnou odchylkou 0,014. Najděte pravděpodobnost, že odchylka X od jmenovité hodnoty nepřekročí 1 % jmenovité hodnoty. Odpovědi
https://pandia.ru/text/78/455/images/image116_9.gif" width="14" height="110 src="> b) 0 pro x≤-3, F(x)= vlevo"> 3.10.
a)f(x)=, b) Р(3,1≤Х≤3,7) ≈0,8185. 3.11.
|x|≥0,6. 3.12.
(-0,5;-0,1). 3.13.
a) P(9,8≤Х≤10,4) ≈0,6562. 3.14.
0,111. 3.15.
a = 1,2. 3.16.
(-6;30). 3.17.
0,4%.

![]()

 1.2.
p4 = 0,1; 0 při x≤-1,
1.2.
p4 = 0,1; 0 při x≤-1,

 (obr.5)
(obr.5) https://pandia.ru/text/78/455/images/image038_17.gif" width="14" height="86"> 0 pro x≤a,
https://pandia.ru/text/78/455/images/image038_17.gif" width="14" height="86"> 0 pro x≤a, ,
, Normální křivka je symetrická vzhledem k přímce x=m, má maximum v x=a, rovné .
Normální křivka je symetrická vzhledem k přímce x=m, má maximum v x=a, rovné .
![]() ,
,![]()
![]()
